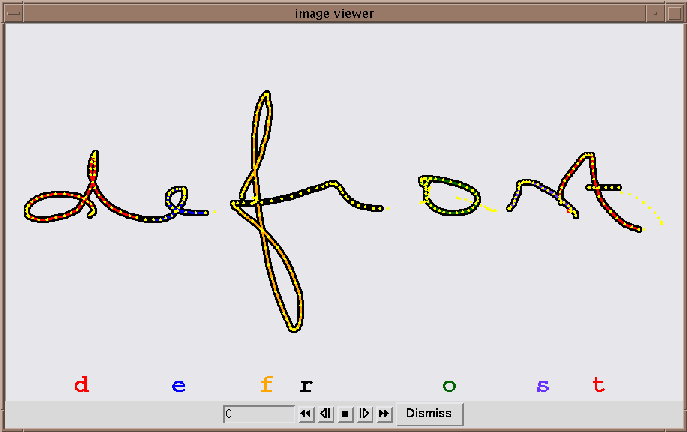
The NICI stroke-based recognizer of on-line handwriting

Introduction and background
The NICI stroke-based recognizer of on-line handwriting was developed
on the basis of knowledge on the handwriting production process.
Initially, it started as a playful experiment to see how far we would
get in handwriting recognition if we used pen-tip velocity as a basic
piece of information in handwriting recognition. From the very beginning
of on-line handwriting recognition attempts, the writer's movements were
considered as a kind of nuisance or strange noise.
Another argument which is often heard is that the movements are more
writer-dependent than the shape of the ink trace.
As a consequence, in many approaches it is assumed that the movement
information should be removed before the actual pattern classification or
feature extraction takes place.
Usually, this is done by some form of spatial resampling or the calculation
of Freeman codes for equal-length segments along the ink trace. We took
the opposite approach - without too high expectations - and tried to
exploit the knowledge which has been collected on the human handwriting
process at NICI since 1976. Assuming equidistant sampling in time, we
analyze the trajectory of the pen-tip, looking for regularities and lawfulnes
in the handwriting process. A number of examples are given in a few live
demos. The 'atomic' component of the handwriting
signal is in our view the velocity-based stroke (VBS). We found out, that
the approach is in fact quite fruitful. The majority of the writers produce
ballistic movements without too many hesitations or other accidents.
Heuristics can be applied to handle the statistical outliers. The approach is
not suited for children's handwriting or handwriting with tremor.

History
- Mid-seventies: digitizer tablets become available. Using a resistive
or capacitive technique and analog to digital conversion, the
pen-tip position could be measured. NICI starts doing handwriting
production research. Names: Teulings, Maarse, van Galen, Thomassen.
- Mid-eighties: a critical mass of knowledge on handwriting signals and
underlying human movement control processes is available at NICI.
Work on the simulation of handwriting movement starts.
In England, the National Physics Lab produced one of the first
Electronic Paper units: an integrated plasma display and digitizer,
connected to a 68000 processor.
- Esprit project "Image and Movement Understanding, P419" (1987). Development
of basic tools for on-line handwriting signal processing. First
handwriting recognition attempt, based on a syntactical, symbolical
approach. After heavily quantizing features of strokes in handwriting,
strings of stroke codes were generated and used for string matching.
Results were limited due to the variability in handwriting.
Small changes in the metric feature domain lead to discrete jumps in
the symbolic domain, which were difficult to handle gracefully.
To us, this became a point of insight as regards the brittleness of
a strict rule-based approach. Useful ideas were developed in the area
of geometric normalisation of the handwriting and the handling of
uncertainty of global word parameters such as slant, size and orientation.
Histogram-based estimation of the lineation in isolated words was
developed. In hindsight, the goals were a little too high, especially
if one considers the available computing power at that time. To counteract
this, a parallel processing scheme was used based on processes running
on several VAXstations, and exchanging information via the file system
which was used as the blackboard. Also, at this time, the problem of
word segmentation was underestimated. We had writers produce several DIN A4 pages of
handwriting which were entered into our system. Segmenting into
lines was easy, segmenting into words was already difficult because
only bottom-up information was used. Partners in the project were:
DIST, University of Genoa, Italy; Captec, Ireland; VDS, Italy; NICI,
Nijmegen University, The Netherlands. Contacts were made with another
famous and innovative Esprit project of that time, P295, including
AEG, Philips, Olivetti, Plessey, which was centered around the role
of paper in the automated office. Their work included on-line and
off-line recognition and document analysis.
- Esprit project 5204 "Papyrus" (1990). Simplifying the goals, and realizing that
a single approach may not be powerful enough, a new project was started
with the goal of producing pen-based applications, using an integrated
handwriting recognizer which combines results from several independently
developed recognizers. Given the major processor at that time (the 386),
it seemed clear that a dedicated board was needed for the computations.
At about this time Microsoft starts releasing information on "Pen Windows".
Partners involved: Olivetti (main contractor), Pacer, Captec,
ABC (later EO, well known for their innovative "Personal Communicator"),
and the university partners DIST, NTU and NICI. The application was the
"hospital emergency entrance" environment, with a goal of improving and
speeding up the patient-based information processing. Later Digital joined
this consortium temporarily. What appeared very succesful was the
combination of the several
(cursive and mixed handwriting) recognizers.
It appeared very difficult however, to achieve the goals at the application
level within two years. With the upcoming multimedia wave, Olivetti shifted
their R&D attention in that latter direction.
- At NICI, research continued, now focussing on the problem of within-writer
variability and between-writer style variation. These problems seemed
to be very basic and essential, also to the Gryphon research group at
HP Labs, Bristol UK. In 1993, a collaboration project between NICI and
HP started.
- The UNIPEN project.
The first impulse to UNIPEN was given at the 11th IAPR-IEEE International Conference on
Pattern Recognition, in September 1992, by a group of experts, the Technical Committee 11 of
the IAPR, Professor Rejean Plamondon chairman. Information on the International Association
for Pattern Recognition (IAPR)) and the Technical Committee 11 is available. Two IAPR
delegates (Isabelle Guyon and Lambert Schomaker) were designated to explore the possibility
to create large databases for on-line handwriting recognition research and development.
A small working group was constituted to get the project started. In May 1993, a nucleus of
experts in on-line handwriting recognition (Tetsu Fujisaki (IBM), Ronjon Nag (Lexicus), Sandy
Benett (GO/EO), Dick Lyons (Apple), Yves Chauvin (NetID), Dave Reynolds and Dan
Flickinger (HP), Isabelle Guyon (AT&T) and Lambert Schomaker (NICI)) laid the
foundations of UNIPEN. It was proposed that a common data format would be designed to
facilitate data exchange. It was decided that contacts would be made with the Linguistic Data
Consortium (LDC) and the National Institute of Standards and Technologies (NIST) to get the
data distributed and arbitrate benchmarks.
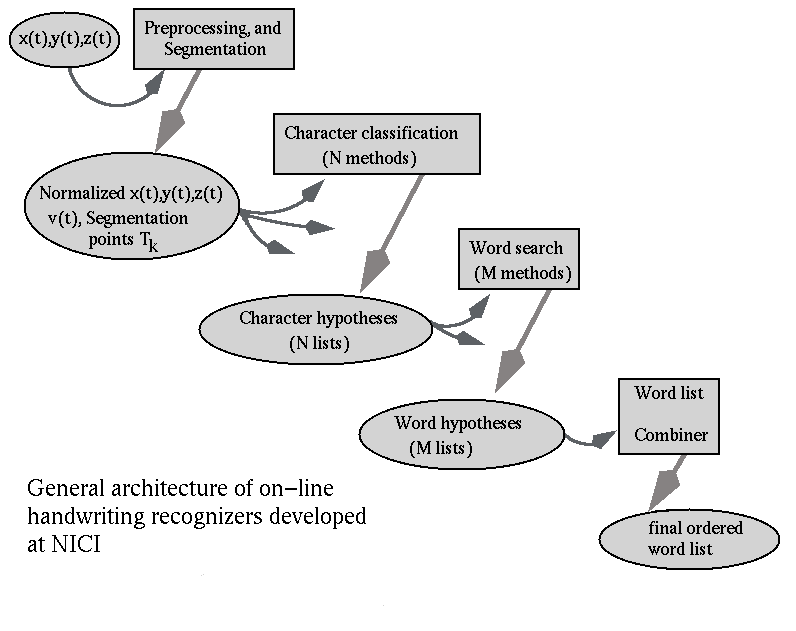
Processing steps in the NICI stroke-based recognizer
The basic design philosophy was introduced in the following paper:
Schomaker, L.R.B., & Teulings, H.-L. (1990).
A Handwriting Recognition System based on the
Properties and Architectures of the Human Motor System.
Proceedings of the International
Workshop on Frontiers in Handwriting Recognition (IWFHR).
(pp. 195-211). Montreal: CENPARMI Concordia.
Processing steps:
The system is organized as a pipeline, hierarchically going up from
individual sample points, to strokes, to letters, and finally to
words.
Performance
Performances of recognizers are difficult to measure, due to the large
number of variables involved. It is like the fuel consumption by cars.
The manufacturer will tell you a figure, but in practice, it is quite
a different story. These are a number of factors influencing recognition
rate and its reliability in recognizers of mixed-style handwriting:
- How many writers produced what amount of data? This determines
a
confidence band of percentages
- Was the writer sample really heterogeneous, in terms of education
level, cultural background, handwriting styles, or were a few
co-developers of the system creating a small set of really clean data?
- What is the amount of advance knowledge used (dictionary size,
language statistics) used by the system?
- Were there separate training sets and test sets?
- How often did the
authors iterate between training set and test set? There are
occasions where a PhD student worked four years on a particular
training-set/test-set pair. You may guess what effect that
has on reported recognition rates.
- Were the writers
in the test set and the training set different persons?
- Were there different words in the test set and the training set?
- Was the recording situation realistic (writing letters, notes) or
was the situation artificial, prompting for individual words?
- What was the quality of the data: The annotation, the segmentation?
Was there a lot of manual cleaning up and pre-segmentation of the data
or did the data come directly from a digitizer in a realistic live setup?
Thus, recognition results should be interpreted with extreme caution.
The rates are seldomly underestimated in literature.
For what it is worth, the next figure gives a distribution of recognition
rates in an 'unseen group of writers' for the stroke-based recognizer.
It is the top-word recognition rate of the basic system: "How often was
the system's best guess indeed correct". If the top word is not OK,
the correct word may be the system's second or later guess, but this is
ignored here. No word-shape information or linguistic statistics were used.
Just searching for individual letters (all must be found). This means that
all fused letters and spelling errors will lead to a missed word!
Lexicon size was 250 words, each writer wrote 45 words. Results of recognizer
version of '95:
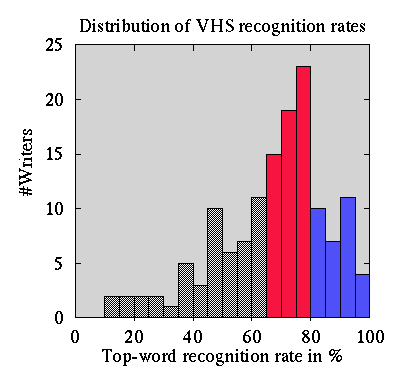
Note that when this system meets unseen writers, a substantial part of
them will have low recognition rates. For example, some of the writers
will write small 'all-caps' letters, claiming that such is their lower case
handwriting. The average processing time per word on a HP-UX 9000/735
workstation was 215ms.
This recognizer is only one of several methods we have tried over the
last few years. It is our oldest method and still performs best as regards
speed and recognition performance, although much can (and will) be improved.
Initially started as a pure connected-cursive recognizer, the approach
gradually allowed for incorporating mixed handwriting and isolated handprint,
as well. Other approaches developed at NICI are a character-based variant
of this recognizer, and a number of other post-processing methods than
graph-based LR search are being explored. Currently, the system is being
retrained with UNIPEN data and a richer stroke feature vector.
Working demo
The recognizer described here has been improved considerably and has
been developed into a larger system
during 1999-2000, for live demos in a Dutch museum (Scryption) and on
the 7th IWFHR conference. This system combines the stroke-based
approach as described above with several independent character classifiers
in a multiple-agent setup. It is dubbed dScript.
dScript Demo description
Other interesting material:
 Handwriting Recognition and Document Analysis Conferences
Handwriting Recognition and Document Analysis Conferences
- Pen & Mobile Computing
- NICI Handwriting Recognition Group home page
- UNIPEN tools
schomakerOai.rug.nl