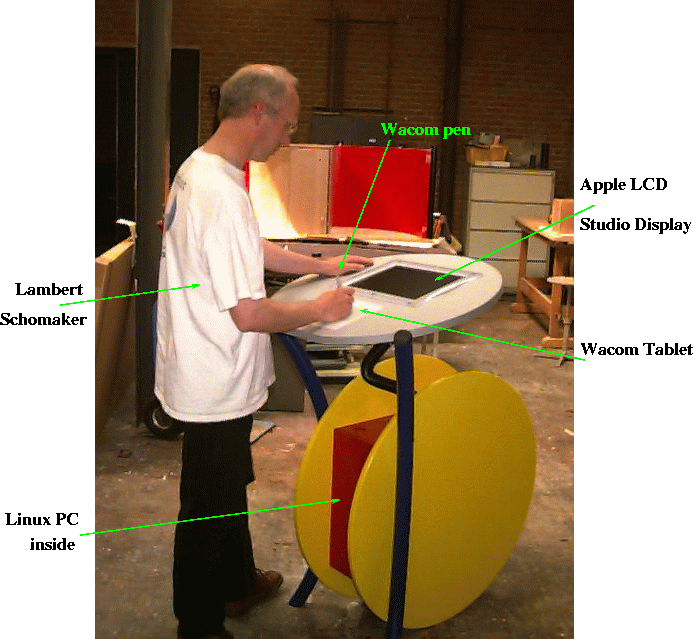
The application
Goal of the dScript system is 1) to promote handwriting recognition in general, 2) to demonstrate our handwriting expertise in a real application. As such, our system has been a great succes. Two versions of the system have been on display at different museums in The Netherlands. Visitors of these museums have shown a large interest in using the system, even when the dScript makes some recognition mistakes.
For the current application of dScript, the goal for the writer is to write one out of about 2800 Dutch city names, like Nijmegen, Amsterdam or Arnhem.
The idea is that if dScript recognizes the city name, the city weapon is displayed, being a reward to the writer.
The user-agent
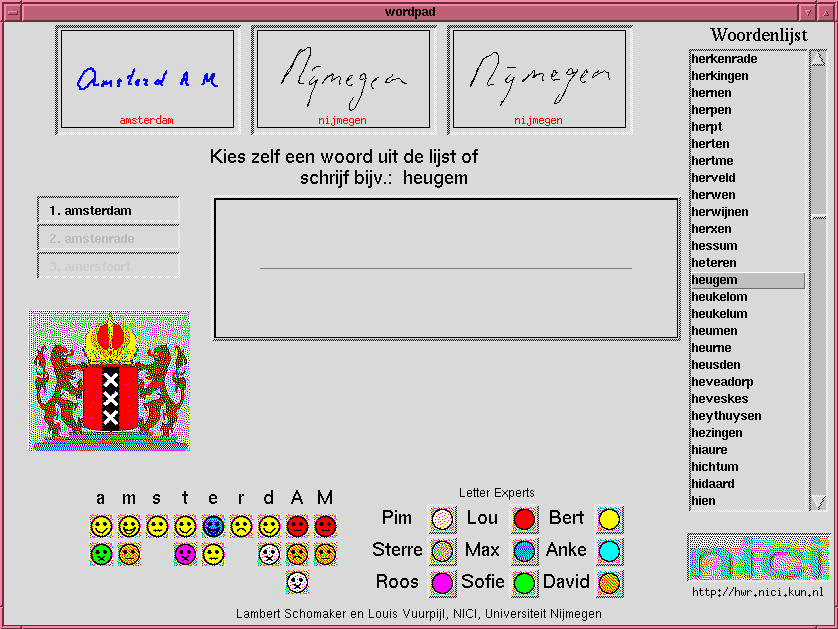
Consider Figure 2 below:
This figure depicts the user interface of dScript, comprising:
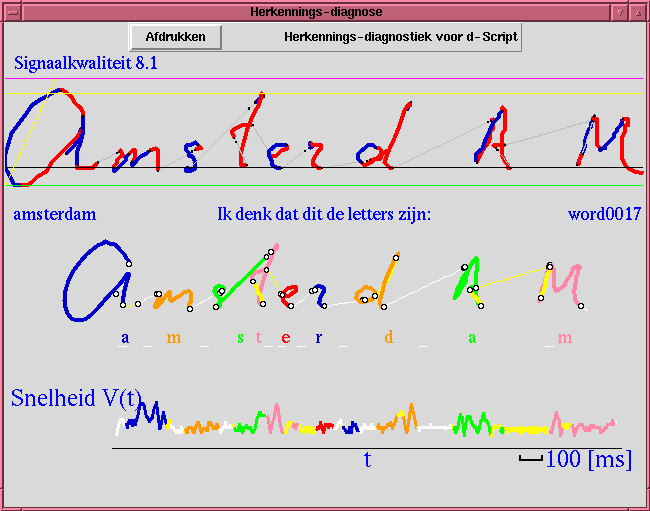
Consider Figure 3 below:
(Schomaker)
(Schomaker)
(Schomaker)
(Vuurpijl)
(Schomaker)
(Schomaker)
(Schomaker)
(Schomaker)
(Wang)
The experiments, necessary for combining the opinions of these
agents and tuning the decision process, have been performed by
Merijn van Erp.
F. Wang, L. Vuurpijl and L. Schomaker (2000, in press). Support Vector Machines for the classification of
Western Handwritten Capitals Proceedings of the Seventh International Workshop on Frontiers in
Handwriting Recognition (7th IWFHR).
Schomaker, L.R.B., & Teulings, H.-L. (1990).
A Handwriting Recognition System based on the Properties and Architectures
of the Human Motor System.
Proceedings of the International Workshop on Frontiers in Handwriting
Recognition (IWFHR) . (pp. 195-211). Montreal: CENPARMI Concordia.
Schomaker, L.R.B. (1993).
Using Stroke- or Character-based Self-organizing Maps
in the Recognition of On-line, Connected Cursive Script.
Pattern Recognition , 26(3), 443-450.
Vuurpijl, L. & Schomaker, L. (1997). Finding structure in diversity: A hierarchical
clustering method for the categorization of allographs in handwriting, Proceedings of the
Fourth International Conference on Document Analysis and Recognition, Piscataway (NJ): IEEE
Computer Society, p. 387-393. ISBN 981-02-3084-2
Vuurpijl, L. & Schomaker, L. (1998).
A framework for using multiple classifiers in a multiple-agent
architecture. Proceedings of the Third European Workshop on Handwriting
Analysis and Recognition, 14-15 July, 1998, London: The Institution of
Electrical Engineers, Digest Number 1998/440, (ISSN 0963-3308), pp. 8/1-8/6
Vuurpijl, L. & Schomaker, L. (1998).
Multiple-agent architectures for the classification of handwritten text.
Proceedings of IWFHR'98, 12-14 August, Taejon, Korea, pp. 335-346.
The monitor-agent
The handwriting experts
 Pim
Pim
This is a character classifier.
The feature vector consists of a monochrome image of 16x16 pixels.
It uses simple nearest-neighbour search, based on a weighted Euclidean
distance measure. The squared feature value differences are weighted by the
inverse of that feature's variance.
The character prototypes are organized as a flat list.
The classifier is invoked only on (series of) ink blobs, which
are combined in a sliding window containing a variable number of ink blobs.
This classifier has been trained on characters from within a handprint style
with isolated characters.
 Sterre
Sterre
This letter expert is actually an agent which tries to propose alternative
solutions for known character confusions, or, alternatively, to rule out
character hypotheses for which conflicting evidence can be found. Mostly,
this is done by reshuffling the confidence measure of the involved character
hypotheses.
For example, an l which is crossed later, might be a
t. The information
which is used at this stage is based on the geometrical relations between the
rectangles containing ink blobs, the estimated lineation, and in particular,
the presence of horizontal bars, dots, periods and commas.
 Roos
Roos
This is a character classifier.
The feature vector consists of a number of dedicated geometric features for
characters, such as vectors radiating from the center of gravity of a shape,
each with length, and angle.
It uses simple nearest-neighbour search, based on a weighted Euclidean
distance measure. The squared feature value differences are weighted by the
inverse of that feature's variance.
The character prototypes are organized as a flat list.
The matching of a prototype occurs with a window size of a varying number
of strokes at all possible stroke-start positions in the ink.
This classifier has been trained on characters from within a mixed-style
context.
 Lou
Lou
This is a character classifier.
The feature vector consists of normalized (x,y) coordinates, augmented with
the running angle f, which is represented as a (cos(f),sin(f)) pair.
It uses
simple nearest-neighbour search, based on the usual Euclidean distance measure.
The character prototypes are organized as a flat list. However, this list
of prototypes has been developed using N-ary hierarchical clustering on a
large training set.
The matching of a prototype occurs with a window size of a varying number
of strokes at all possible stroke-start positions in the ink. A special
attention is given to possible (upper case) characters at the beginnning of
a word, on the left.
This classifier has been trained on UPPER-CASE characters from within a
mixed-style word context.
 Max
Max
This is a character classifier.
The feature vector consists of normalized (x,y) coordinates, augmented with
the running angle f, which is represented as a (cos(f),sin(f)) pair.
It uses
simple nearest-neighbour search, based on the usual Euclidean distance measure.
The character prototypes are organized as a tree, a hierarchical Kohonen
self-organized map, 2x2 nodes per map, in four layers. This speeds up the
matching process, at the cost of occasionally derailing due to an early
wrong decision.
The matching of a prototype occurs with a window size of a varying number
of strokes at all possible stroke-start positions in the ink.
This classifier has been trained on characters from within a mixed-style
but mostly cursive word context.
 Sofie
Sofie
This is a character classifier.
The feature vector consists of normalized (x,y) coordinates, augmented with
the running angle f, which is represented as a (cos(f),sin(f)) pair.
It uses simple nearest-neighbour search, based on a weighted Euclidean
distance measure. The squared feature value differences are weighted by the
inverse of that feature's variance.
The character prototypes are organized as a flat list.
The matching of a prototype occurs with a window size of a varying number
of strokes at all possible stroke-start positions in the ink.
This classifier has been trained on characters from within a mixed-style
but mostly cursive word context.
 Bert
Bert
This is a character classifier, based on stroke sequences. A character
is defined to consist of a sequence of strokes. A stroke is a trajectory
bounded by two points of high curvature. These points are determined by
computing the velocity signal, finding minima, and segmenting the ink trace.
Each stroke is characterized by 14 features (9 angles, vertical position,
pen up/down, length, loop area). An alphabet of prototypical strokes has
been computed by using a 2D Kohonen self-organized map on 1 million such
strokes. The map contains 20x20 prototypical strokes. A character is in
fact a path of nodes in this 2D map. A Markov model is formed, using the
probabilities of stroke-name transitions within a character. As an example,
the three-stroked letter {a} may be represented by the stroke sequence
{a1/3},{a2/3},{a3/3}.
This classifier has been trained on a large database of mixed styles, but
performs best on connected-cursive handwriting.
 Anke
Anke
This is a character-based classifier, which uses a simple grammar for
consecutive classified pen-down shapes (for instance, an L shape followed
by two - might be a capital E). A number of primitives are classified,
such are straight lines, circles, V shapes and U shapes.
The matching is according to a simple grammar. This classifier is invoked
on series of ink blobs in a variable window.
The classifier has been designed on the basis of a number of clearly
identifiable 'nice' examples.
 David
David
This is a character classifier.
The feature vector consists of a monochrome image of 16x16 pixels.
It uses a neural-network classifier (multi-layer perceptron or MLP) with
four layers (256x48x32x26 is the net architecture).
This classifier has been trained on UPPER-CASE characters from within a
handprint style with isolated characters, also called block print. It is
invoked only on ink blobs which are clearly separated by white space.
References