
The stroke-transition network generates a grid of letter hypotheses for all stroke positions in the word. Words can be constructed from a graph which connects consecutive letter hypotheses in this grid. The total possible number of words can be extremely high (in the order N^M, where N is the average number of letter hypotheses per letter position, and M is the average path length). Due to the ambiguity in cursive script, n > 1 (many shapes will fit very well, locally in the trace) and lexical knowledge must be included. Several techniques are known, such as the 26-way tree (trie) for testing quickly if the current letter path, traced from Left to Right occurs in any word in the lexicon. For ease of use and a simple representation of the lexicon we use binary search in an alphebetically sorted word list, which already gives an acceptable performance (<1s per word).
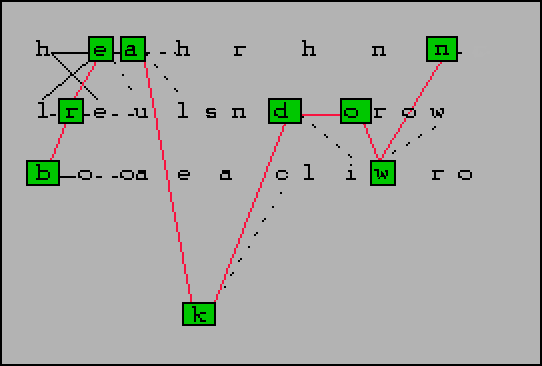
The following figure shows how a path is traced in the letter hypotheses grid.
The amount of confusion shown here is not typical for our recognizer, and can be seen in the character hypotheses grid for many current techniques. This is not to say that the stroke approach and the stroke shape features which we use are the ideal solution. But there is an inherent ambiguity in cursive script. Thus, some of the hypotheses are reasonable (d vs cl, k vs h), whereas others seem strange to the human reader.
A disadvantage of this LR search approach is that a tiny character-classification problem in an otherwise neatly written word makes correct word recognition impossible. Therefore, several other techniques are currently being studied at NICI. As an example, trigrams are often coined as a solution to this brittleness problem. However, if a single character is written sloppy, this affects three trigrams of the target word, which span five character positions in the word: a considerable portion (if not the whole) of most words:
#houses#
#ho
hou
ous
use
ses
es#
#ho*ses# (missing u)
Only '#ho', 'ses', and 'es#' are present of the possible six trigrams.
But a more serious problem is that, contrary to the situation
in machine print and hand-print, in cursive and mixed script we really
don't know exactly how many letters there are in the missing unrecognized
word fragment.
Please refer to our Publications when using anything from the shown material.

 to NICI's on-line handwriting recognizer description
to NICI's on-line handwriting recognizer description
to NICI's Java-based Handwriting Demos page
 Handwriting Recognition and Document Analysis Conferences Pen & Mobile Computing NICI Handwriting Recognition Group home page UNIPEN tools
Handwriting Recognition and Document Analysis Conferences Pen & Mobile Computing NICI Handwriting Recognition Group home page UNIPEN tools
Copyright Lambert Schomaker (April 1, 1996)
since 1/Mar/1996