
practicum signaalanalyse
deadline: vrijdag 27 februari om 9 uur 's ochtends
In dit eerste practicum worden geluiden nader bekeken. Hierbij
wordt ingegaan op de wijze waarop (spraak-) geluid in het tijd- en
frequentiedomein kunnen worden beschreven. Voor de
frequentiedomeinanalyse wordt in dit practicum gebruik gemaakt van
standaard geluidsanalyse methoden op basis van FFT-analyses.
Centraal staan de vragen:
De vorm van het eerste practicum is als volgt:
De voorbereiding vergt nogal wat tijd. Zonder goede voorbereiding is het practicum niet in de twee practica (à 4 uur) uit te voeren. Lees dus voor het eerste practicum de theorie over de fouriertransformatie door. Je kan natuurlijk ook altijd buiten de practicumuren aan het werk gaan. Als je vragen hebt kun je Maria () mailen.
Tijdens dit practicum wordt gebruik gemaakt van Matlab. Het practicum kan zowel uitgevoerd worden onder Linux als onder Windows. Matlab opdrachten zoals hieronder kunnen via een muis-selectie (onder Linux) als met control-C en control-V (Windows) in een Matlab omgeving worden uitgevoerd. Bijvoorbeeld, het aan Matlab aanbieden van:
help soundsc
Geeft als resultaat:
SOUNDSC Autoscale and play vector as sound.
SOUNDSC(Y,...) is the same as SOUND(Y,...) except the data is
scaled so that the sound is played as loud as possible without
clipping. The mean of the data is removed.
SOUNDSC(Y,...,SLIM) where SLIM = [SLOW SHIGH] linearly scales
values in Y in the range [SLOW, SHIGH] to [-1, 1]. Values
outside this range are not clipped. By default, SLIM is
[MIN(Y) MAX(Y)].
See also SOUND, WAVPLAY, WAVRECORD.
De meeste wiskundige notaties in deze tekst zijn in een soort pseudo-matlab taaltje of in de vorm van echte Matlab-commando's.
practicum spraakherkenning 1
practicum spraakherkenning 2
deadline: vrijdag 13 maart om 9 uur 's ochtends
In dit practicum maak je kennis met een commercieel dicteer
systeem: Dragon NaturallySpeaking. Dit is een product van
Nuance, zij hebben dit systeem voor ons beschikbaar gesteld en
zijn zeer geïnteresseerd in onze bevindingen. We werken hier
met de preferred version. Dit houdt in dat je dit systeem
bijvoorbeeld in Word, Excel, Outlook kunt gebruiken, maar ook
Windowstoepassingen kunt starten en op internet kunt chatten. Wij
gebruiken het in dit practicum alleen in Word, omdat het ons
alleen om de herkenningsprestatie gaat.
Hieronder staan een aantal dingen die handig zijn voordat je kunt
beginnen met dicteren. Verder staan de (spraak)commando's die je
voor de opdrachten nodig hebt in de tabel.
nieuwe gebruiker
Menu: NaturallySpeaking -> Gebruiker openen... -> Nieuw...
microfoon
Let op dat de microfoon de juiste positie heeft. Deze moet vlak
naast je mond staan, de afstand tot je mond mag dichtbij zijn,
maar niet deze niet aanraken.Zorg ook voor een constante
positie.
Het aan en uitzetten van de microfoon: '+' knop op het numerieke
deel van het toetsenbord.
dicteren
Het dicteren is gewoon het voorlezen van de tekst. Wat je niet
moet vergeten is, als je leestekens (punt, komma, etc) wilt dan
moet je dit expliciet aangeven (zie stemcommando's hieronder). Dit
geldt ook als je een nieuwe regel of alinea wilt starten.
Lees de tekst regel voor regel voor. Kijk of de regel goed wordt
herkend, anders corrigeer je deze op de manier zoals hieronder
wordt beschreven. Zorg dat het systeem in normale modus staat, dan
kun je dicteren en stemcommando's doorelkaar gebruiken.
Voorbeeldcommando's: zeg "Wat kan ik zeggen?"
corrigeren
Wil je een woord corrigeren, zorg dan dat deze geselecteerd is en
selecteer vervolgens met behulp van het correctiescherm het juiste
woord. Je moet dit op deze manier doen, omdat op deze manier het
systeem nog kan leren. Delete/backspace gebruik zorgt niet voor
verbetering van het systeem.
selectie woord
Met stemcommando: het correctiescherm verschijnt vanzelf
Met muis/toetsenbord: correctie scherm: '-' knop op het numerieke deel van het toetsenbord
| navigeren, selecteren, wissen | |
|---|---|
| Zeg... | Dit wil je |
Nieuwe regel |
Een nieuwe regel toevoegen |
Nieuwe alinea |
Een nieuwe alinea toevoegen |
Spatiebalk |
Een spatie invoegen |
Tab |
Een tab invoegen |
Ga naar ‹begin› van ‹document› |
Naar het begin/eind van document/regel |
Selecteer [tekst] |
Selecteren van de tekst |
Wis datof schrap dat |
Verwijderen wat je net gezegd hebt |
| opmaak | |
|---|---|
| Zeg... | Dit wil je |
Maak dat ‹vet› |
Geselecteerde tekst vet (of cursief) |
Onderstreep dat |
Geselecteerde tekst onderstrepen |
Centreer dat |
Centreren |
Links uitlijnen |
Linksuitgelijnen |
Herstel dat |
Opmaak wordt weer normaal |
| leestekens | |
|---|---|
| Zeg... | Dit wil je |
Komma |
, |
Punt |
. |
Uitroepteken |
! |
Vraagteken |
? |
Streepje |
- |
Dubbele punt |
: |
Enkel aanhalingsteken openen Enkel aanhalingsteken sluiten |
' ' |
Aanhalingsteken openen Aanhalingsteken sluiten |
" " |
haakje openen haakje sluiten |
( ) |
Hieronder nog een korte uitleg van het programma Audacity, dat wordt gebruikt bij het tweede deel van het practicum over spraakherkenning.
openen, opnemen, opslaan
Openen Audacity: Start -> Programs -> Audacity (Je
moet versie 1.2.0-pre4 gebruiken. Dit controleer je door in
Audacity: Hulp -> Over Audacity.) Eigen spraak kun je
opnemen met behulp van de knoppen Opnemen, Pauzeren,
Stoppen, etc. Onder de knoppen voor het opnemen kun je
aangeven waar je geluid vandaan komt (microfoon, cd-rom, etc). Als
je het bestand wil opslaan als een wav-file ga dan naar
Bestand -> Exporteren als WAV.
twee signalen optellen
Open het eerste bestand en importeer het tweede bestand met
Project -> Audio importeren. Als je dit op deze
manier doet dan wordt het in Audacity bij elkaar gezet. Je slaat
het geheel dan op bovenstaande wijze op.
signaal-ruisverhouding
Als je een bestand opent, zie je links naast de weergave van het
signaal twee schalen. Door de schaal van + en
- aan te passen bepaal je de
signaal-ruisverhouding. (Met de andere schaal bepaal je de
hoeveelheid die door ieder kanaal (links of rechts) gaat).
gelijk maken van het signaal
Na het optellen moet je zorgen dat de frequentie en de lengtes van
de beide bestanden gelijk zijn. Eerst pas je de frequentie aan en
daarna pas de lengte. Dit gaat als volgt:
Frequentie: naast het signaal Audiospoor -> Frequentie
instellen
Lengte: selecteren overbodige deel en te verwijderen door
Bewerken -> verwijderen
practicum spraakanalyse
deadline: vrijdag 20 maart om 9 uur 's ochtends
Als gevolg van bijvoorbeeld ruis, coarticulatie en verschillende sprekers is de spraak die je hoort lang niet zo constant als het lijkt. Toch kunnen mensen hier erg goed mee overweg. De modellen die in het college zijn geïntroduceerd hoeven niet met deze variatie om te kunnen gaan, ze verwachten een gelabelde feature-input. In dit practicum gaan we allereerst kijken naar de variabiliteit van spraak en daarna gaan we twee van verschillende variatie-bronnen nader bestuderen; spreker variatie en spreek snelheid variatie. Je hebt voor dit practicum koptelefoons nodig en de functionstest toolbox. In principe werk je in groepjes van twee omdat je spraaksignalen met elkaar wilt vergelijken.
voorbereiding
mkdir
wav/).
practicum CPSP 1
practicum CPSP 2
deadline: vrijdag 10 april om 9 uur 's ochtends
Werken met CPSP is fysisch intuïtiever dan met FFT-spectra waar bijvoorbeeld de noodzaak voor windowen tot allerlei complicaties leidt. Het gebruik van CPSP vereist echter zowel wat kennis over het auditieve systeem (in het bijzonder van het basilair membraan, dat een onderdeel van de cochlea is), als wat kennis over het het gebruik van het een BM-model. Dit BM-model vormt een onderdeel van de CPSP software.
In vergelijking met het natuurlijke systeem is er een belangrijke
overeenkomst die doorgaans niet door andere signaalanalyse
methoden gegarandeerd kan worden: de garantie van
continuïteit in plaats (die overeenkomt met frequentie) en
tijd. Er is ook een belangrijk verschil met het natuurlijke
systeem: het gebruikte model is volledig lineair, terwijl het
natuurlijke systeem juist zeer sterk niet-lineair is. Hiervoor
wordt enigszins gecorrigeerd door de output van het model in
decibel weer te geven. Een lineair model maakt de toepassing als
signaalanalyse methode een stuk gemakkelijker (alternatieve
methoden zoals op basis van de FFT zijn ook lineair). Het is
interessant dat hoewel de natuurlijke cochlea sterk niet-lineair
is, de totaal-performance van het gehele auditieve systeem in veel
gevallen verrassend lineair lijkt. Dit blijk uit onder andere het
menselijke vermogen om een mengsel van geluidsbronnen A +
B te kunnen scheiden. Voor een lineair systeem
L geldt immers:
L(A + B) = L(A) + L(B)
en niet:
L(A + B) = L(A) + L(A,B) + L(B)
met L(A,B) kruistermen afhankelijk van zowel A als B
Kruistermen zijn in de regel moeilijk te vermijden in
niet-lineaire systemen en zorgen ervoor dat informatie over bron
A besmet wordt met informatie over bron
B en vice versa.
De vorm van het practicum is als volgt:
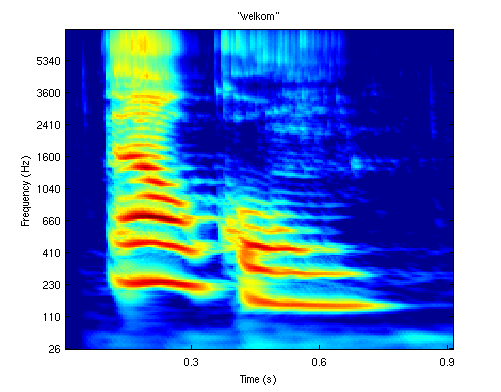
Hieronder een voorbeeld van een cochleogram: "welkom" uitgesproken door een vrouwelijke spreker.
postadres
Auditory Cognition Group
Kunstmatige Intelligentie
Rijksuniversiteit Groningen
Postbus 407
9700 AK Groningen
bezoekadres
Bernoulliborg
Nijenborgh 9
9747 AG Groningen