


Next: Audio-visual speech synthesis
Up: Audio-Visual Speech Synthesis
Previous: Audio-Visual Speech Synthesis
In the last two decades, a variety of synthetic faces have been designed
all over the world with the objective of their animation. The quality of
facial models goes from a simple electronic curve on an oscilloscope,
through a wide range of pre-stored human face shapes and more or less
caricatural 2D vector-driven models of the most salient human face
contours, to a very natural rendering of a 3D model (by mapping of real
photographs on it, for instance). I think that, as in the case of acoustic
speech synthesis, one must differentiate the final model from its animation
technique. I suggest the reader refer to [46] for a turorial
presentation of the techniques and methods used in facial animation. To
sum up, Figure B.3 gives a classification of the most
noticeable publications of designed systems along these two criteria. For
simplification purposes, the table does not consider the work done by
investigators to develop or apply the models cited, nor to synchronise them
with speech synthesizers. Of course, the control parameters of a
rule-driven model may be given by a code-book, after analysis of the
acoustic wave-form, so the Y-axis could have been presented differently.
However, the table aims at showing the basic characteristics of the various
approaches by assigning the most suitable animation technique to a given
model.

Figure B.3
: Classification of best-known face synthesizers based on the
kind of facial model developed (X-axis), and on its underlying method
of animation (Y-axis). Only the first author and date of publication
are quoted.
Whatever the facial model, it may be animated for speech by three main methods:
{
- A direct mapping from acoustics to geometry creates a correspondence
between the energy in a filtered bandwith of the speech signal and the
voltage input of an oscilloscope, and therefore with the horizontal or
vertical size of an elliptical image [37,96]. An indirect
mapping may also be achieved through a stochastic network which outputs a
given image from a parametrization of the speech signal, after training
of the network in order to make it match any possible input with its
corresponding output as accurately as possible. Simons and
Cox [313] used a Hidden Markov network, whereas Morishima
et al. [230] preferred a connectionist network, for instance.
In both, the inputs of the networks were LPC parameters calculated from
the speech signal.
- When the facial model has previously been designed so that it can be
animated through control parameters, it is possible to elaborate rules
which simulate the gestural movements of the face. These commands can be
based on a geometrical parametrization, such as jaw rotation or mouth
width for instance, in the case of the 2D models by Brooke [45]
or Guiard-Marigny [132], or the 3D models by Parke [258],
Cohen and Massaro [71], or Guiard-Marigny
et al. [133]. The commands can also be based on an
anatomical description, such as the muscle actions simulated in the 3D
models by Platt and Badler [273], Waters [355],
Magnenat-Thalmann et al. [202], or Viaud [345].
- Facial models may only mimic a closed set of human expressions,
whatever the tool used to create them:
- a set of 2D vectors [227,366],
- simplified photos [16]; (Mohamadi, 1993),
- hand-drawn mouth-shapes [215]),
- 3D reconstructions of 2D images [256]),
- 3D digitizing of a mannequin using a laser
scanner [203,238,160,166], or even
- direct computer-assisted sculpting [255].
If no control parameters can be applied to the structure obtained in
order to deform it and so generate different expressions, and if
digitizing of multiple expressions is impossible, hand-modification by an
expert is necessary in order to create a set of relevant key-frame
images. The pre-stored images can then be concatenated as in cartoons,
so that a skilled animator may achieve coherent animation. Such a
technique has been widely employed, since it only requires a superficial
model of the face, and as little physiological knowledge of speech
production is needed to modify the external texture so that natural
images can be duplicated (rotoscoping technique).
I also want to mention two other techniques that directly rely on human
gestures:
- Expression slaving consists of the automatic measurement of
geometrical characteristics (reference points or anatomical measurements)
of a speakers face, which are mapped onto a facial model for local
deformation [18,337,363,259,177].
In the computed-generated animation The Audition [224],
the facial expressions of a synthetic dog are mapped onto its facial
model from natural deformations automatically extracted from a human
speakers face [259].
- Attempts have also been made to map expressions to a facial model
from control commands driven in real-time by the hand of a skilled
puppeteer [79]. In a famous computer-generated French TV series,
Canaille Peluche
 , the body and face gestures of Mat, the synthetic
ghost, are so created. Finally, a deformation that is rather based on
the texture than on the shape of the model can be achieved by a mapping
of various natural photos on the model [166].
, the body and face gestures of Mat, the synthetic
ghost, are so created. Finally, a deformation that is rather based on
the texture than on the shape of the model can be achieved by a mapping
of various natural photos on the model [166].
The basic principles of these various animation techniques are represented
in figure B.4 .
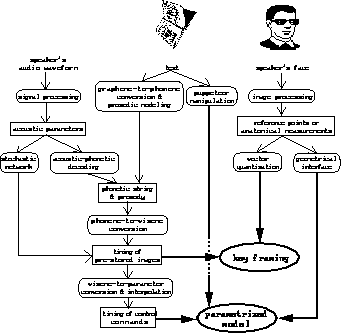
Figure B.4
: General architecture of Facial Animation showing the possible
techniques.
Next: Audio-visual speech synthesis
Up: Audio-Visual Speech Synthesis
Previous: Audio-Visual Speech Synthesis
 Esprit Project 8579/MIAMI (Schomaker et al., '95)
Esprit Project 8579/MIAMI (Schomaker et al., '95)
Thu May 18 16:00:17 MET DST 1995