In the area of speech perception, several models have been proposed to
account for speech recognition in noise or for the perception of
paradoxical stimuli [52,208,209,53,292,348].
However, Summerfield addressed the main theoretical issues and discussed
them in the light of experimental data and of general theories of speech
perception [332]. He described five different architectural
structures that may solve the problem of audio-visual fusion in the
perception of speech. We here revisit those five models in order to better
fit them into the general principles presented in the above section. The
proposed structures are presented in the following sections. They are
finally put into relation with the general principles.
- Direct Identification Model (DI)
- The Direct Identification model of
audio-visual configurations is based upon the Lexical Access From
Spectra by Klatt [157]. It has been turned into a
Lexical Access from Spectra and Face Parameters. The input signals
are here directly transmitted to the bimodal classifier. This classifier
may be, for instance, a bimodal (or bivectorial) lexicon in which the
prototype the closest to the input is selected (see
figure C.1 ).
Basics of the model: There is no common representation level over the two
modalities between the signal and the percept.
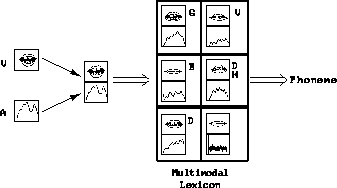
Figure C.1
: Schematic of the Direct Identification (DI) model
- Separated Identification Model (SI)
- In the Separated Identification
model, the visual and the auditory input are separately identified
through two parallel identification processes. Fusion of the phonemes or
phonetic features across each modality occurs after this identification.
Fusion can be processed with logical data, such as in the VPAM model
(Vision Place Auditory Mode) where each modality deals with a set of
phonetic features [220,332]. Thus, the place of
articulation of the output is that of the visual input and the mode of
articulation (voiced, nasal, etc.) is that of the auditory input (see
figure C.2 ).
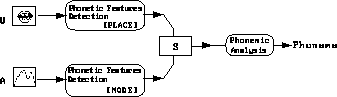
Figure C.2
: Schematic of the VPAM model (example of an SI structure)
(after [332])
Fusion can also be processed with probabilistic data (fuzzy logic). Each
input can be matched against (unimodal) prototypes in order to get two
scores for each category. Then, each pair of data corresponding to the
same category is fused through probabilistic computation. The FLMP
(Fuzzy Logical Model of Perception) falls into this class of models (see
[208,52]).
Basics of the model: The inputs are matched against prototypes (or even
classified) before being integrated.
- Dominant Modality Recoding Model (RD)
- The model of Recoding into the
Dominant Modality sees the auditory modality as a dominant modality in
the perception of speech since it is better suited to it. The visual
input is thus recoded into a representation of this dominant modality.
The selected representation of the auditory modality is the transfer
function of the vocal tract. This transfer function is separately
evaluated from the auditory input (e.g., through cepstral processing)
and from the visual input (through association). Both evaluations are
then fused. The source characteristics (voiced, nasal, etc.) are
evaluated only from the auditory information. The so evaluated pair
source / vocal tract is then sent to the phonemic classifier (see
figure C.3 ).
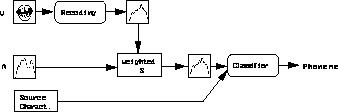
Figure C.3
: Schematic of the Dominant Modality Recoding (RD) model
Basics of the model: The visual modality is recoded into an auditory
metric. Both representations are then integrated into the auditory space
where the categorization takes place.
- Motor Space Recoding Model (MR)
- In the Motor Space Recoding Model,
the two inputs are projected onto an amodal space (which is neither
auditory nor visual). They are then fused within this common space. This
amodal space is the articulatory space of vocal tract configurations.
The visual modality is projected only on the vocal tract space dimensions
where to information can be carried. For instance, the visual modality
may bring information on lip rounding, not on the velum position. The
final representation depends on two possibilities. when there is a
single projection on a dimension (from the auditory input), this
projection makes the final decision. When information from the two
modalities is simultaneously projected upon one dimension (e.g. jaw
height), the final value comes from a weighted sum of both inputs. The
final representation thus obtained is given by the phonemic classifier.
This architecture fits well the Motor Theory of Speech
Perception [187]) and the Realistic Direct Theory of
Speech Perception [108].
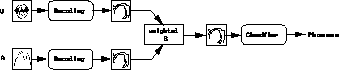
Figure C.4
: Schematic of the Motor Space Recoding (MR) model
Basics of the model: The two modalities are projected upon a common motor
space where they are integrated before final categorization.
- Model of Motor Dynamics
- This last model is the one least developed
by Summerfield. Each modality gives an estimation of the motor dynamics
(mass and force) of the vocal tract. Such an estimation might be based
upon kinematics data (position, velocity and acceleration). The two
pieces of estimation (from each modality) of motor dynamics are fused and
then categorized, describing the identity of phonemes in terms of
time-varying functions rather than articulatory states
traversed [332, page 44,]. The important difference between this
model and the previous one relies in the nature of the motor
representation, as seen as the projection and integration of the sensory
inputs. In fact, the previous model could be given the name AR
(Articulatory Recoding) whereas the current model could be entitled MR in
itself.
However, introducing such a distinction which is relevant to deal with
theories of speech perception is somewhat disputable when dealing with
architectures of audiovisual fusion. We could thus think of other
distinctions that make use of the various propositions found in
literature on the nature of the preprocessing at the input or of the
level of the linguistic units at the output. This is why we prefer to
take only in consideration the architecture called MR, as described in
figure C.4 , since it can regroup ``static'' as well as
``dynamic'' representations of the motor configurations.