Speech production is based on the basic mechanisms of phonation, related to the vibration of the vocal cords, and of vocal articulation, related to the time-varying geometry of the vocal tract responsible of the phonemic structure of speech. Forcing the diaphragm up, air is pushed out from the lungs into the trachea, glottis (the gap between the two vocal cords) and larynx before reaching the upper part of the vocal tube, called vocal tract, formed by pharynx, nasal and oral concavities. The periodical closure of the glottis interrupts the airflow generating a periodic variation of the air pressure whose frequency can be raised to the acoustic range. The harmonic components of this acoustic wave, multiples of the fundamental (pitch frequency), are then modified as long as the air flows through the vocal tract depending on its geometry. The vocal tract, in fact, can be shaped variously by moving the jaw, tongue, lips and velum: in this way the vocal tract implements a time-varying system capable to filter the incoming acoustic wave, reshaping its spectrum and modifying the produced sound.
Speech is the concatenation of elementary units, phones, generally classified as vowels if they correspond to stable configurations of the vocal tract or, alternatively, as consonants if they correspond to transient articulatory movements. Each phone is then characterized by means of a few attributes (open/closed, front/back, oral/nasal, rounded/unrounded) which qualify the articulation manner (fricative like /f/,/s/, plosive like /b/, /p/, nasal like /n/, /m/, ...) and articulation place (labial, dental, alveolar, palatal, glottal).
Some phones, like vowels and a subset of consonants, are accompanied by vocal cords vibration and are called ``voiced'' while other phones, like plosive consonants, are totally independent of cords vibration and are called ``unvoiced''. In correspondence of voiced phones the speech spectrum is shaped, as previously described, in accordance to the geometry of the vocal tract with characteristic energy concentrations around three main peaks called ``formants'', located at increasing frequencies F1, F2 and F3.
An observer skilled in lipreading is able to estimate the likely locations
of formant peaks by computing the transfer function from the configuration
of the visible articulators. This computation is performed through the
estimation of four basic parameters: (i) the length of the vocal tract L,
(ii) the distance d between the glottis and the place of maximum
constriction; (iii) the radius r of the constriction; (iv) the ratio
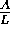 between the area A of the constriction and L. While the
length L can be estimated a priori taking into account the sex and age of
the speaker, the other parameters can be inferred, roughly, from the
visible configuration. If the maximum constriction is located in
correspondence of the mouth, thus involving lips, tongue and teeth as it
happens for labial and dental phones, this estimate is usually reliable. In
contrast, when the maximum constriction is non visible like in velar phones
( /k/, /g/) the estimate is usually very poor.
between the area A of the constriction and L. While the
length L can be estimated a priori taking into account the sex and age of
the speaker, the other parameters can be inferred, roughly, from the
visible configuration. If the maximum constriction is located in
correspondence of the mouth, thus involving lips, tongue and teeth as it
happens for labial and dental phones, this estimate is usually reliable. In
contrast, when the maximum constriction is non visible like in velar phones
( /k/, /g/) the estimate is usually very poor.
Lipreading represents the highest synthesis of human expertise in converting visual inputs into words and then into meanings. It consists of a personal database of knowledge and skills constructed and refined by training, capable to associate virtual sounds to specific mouth shapes, generally called ``viseme'', and therefore infer the underlying acoustic message. The lipreader attention is basically focused on the mouth, including all its components like lips, teeth and tongue, but significant help in comprehension comes also from the entire facial expression.
In lipreading a significant amount of processing is performed by the lipreader himself who is skilled in post-filtering the converted message to recover from errors and from communication lags. Through linguistic and semantic reasoning it is possible to exploit the message redundancy and understand by context: this kind of knowledge-based interpretation is performed by the lipreader in real-time.
Audio-visual speech perception and lipreading rely on two perceptual systems working in cooperation so that, in case of hearing impairments, the visual modality can efficiently integrate or even substitute the auditory modality. It has been demonstrated experimentally that the exploitation of the visual information associated to the movements of the talker lips improves the comprehension of speech: the Signal to Noise Ratio (SNR) is incremented up to 15 dB and the auditory failure is most of times transformed into near-perfect visual comprehension. The visual analysis of the talker face provides different levels of information to the observer improving the discrimination of signal from noise. The opening/closing of the lips is in fact strongly correlated to the signal power and provides useful indications on how the speech stream is segmented. While vowels, on one hand, can be recognized rather easily both through hearing and vision, consonants are conversely very sensitive to noise and the visual analysis often represents the only way for comprehension success. The acoustic cues associated to consonants are usually characterized by low intensity, a very short duration and fine spectral patterning.
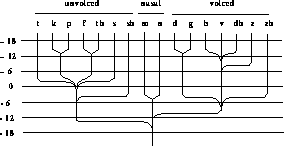
Figure B.1
: Auditory confusion of consonant transitions CV in white noise
with decreasing Signal to Noise Ratio expressed in dB. (From B. Dodd,
R. Campbell, ``Hearing by eye: the psychology of lipreading'', Lawrence
Erlbaum Ass. Publ.)
The auditory confusion graph reported in figure B.1
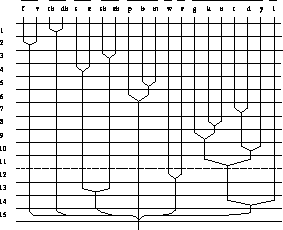
Figure B.2
: Visual confusion of consonant transitions CV in white noise
among adult hearing impaired persons. By decreasing the Signal to Noise
Ratio consonants, which are initially discriminated, are progressively
confused and clustered. When the 11-th cluster is formed (dashed
line), the resulting 9 groups of consonants can be considered distinct
visemes. (From B. Dodd, R. Campbell, :`''Hearing by eye: the psychology
of lipreading'', Lawrence Erlbaum Ass. Publ.)
Place cues are associated, in fact, to mid-high frequencies (above 1 kHz) which are usually scarcely discriminated in most of hearing disorders, on the contrary of nasality and voicing which reside in the lower part of the frequency spectrum. Cues of place, moreover, are characterized by short-time fine spectral structure requiring high frequency and temporal resolution, differently from voicing and nasality cues which are mostly associated to unstructured power distribution over several tens of milliseconds.
In any case, seeing the face of the speaker is evidently of great advantage to speech comprehension and almost necessary in presence of noise or hearing impairments: vision directs the auditor attention, adds redundancy to the signal and provides evidence of those cues which would be irreversibly masked by noise.
In normal verbal communication, the analysis and comprehension of the various articulation movements relies on a bimodal perceptive mechanism for the continuous integration of coherent visual and acoustic stimuli [331] In case of impairments in the acoustic channel, due to distance, noisy environments, transparent barriers like a pane of glass, or to pathologies, the prevalent perceptive task is consequently performed through the visual modality. In this case, only the movements and the expressions of the visible articulatory organs are exploited for comprehension: vertical and horizontal lips opening, vertical jaw displacement, teeth visibility, tongue position and other minor indicators like cheeks inflation and nose contractions.
Results from experimental phonetics show that hearing impaired people behave differently from normal hearing people in lipreading [94,254]. In particular, visemes like bilabial /b, p, m/, fricative /f, v/ and occlusive consonants /t, d/ are recognized by each of them, while other visemes like /k, g/ are recognized only by hearing impaired people. The occurrence of correct recognition for each viseme is also different between normal and hearing impaired people: as an example, hearing impaired people recognize much more successfully nasal consonants /m, n/ than normal hearing people. These two specific differences in phoneme recognition can be hardly explained since velum, which is the primary articulator involved in phonemes like /k, g/ or /m, n/, is not visible and its movements cannot be perceived in lipreading. A possible explanation, stemming from recent results in experimental phonetics, relies on the exploitation of secondary articulation indicators commonly unnoticed by the normal observer.
If a lipreadable visual synthetic output must be provided through the automatic analysis of continuous speech, much attention must be paid to the definition of suitable indicators, capable to describe the visually relevant articulation places (labial, dental and alveolar) with the least residual of ambiguity [205,204,206]. This methodological consideration has been taken into account in the proposed technique by extending the analysis-synthesis region of interest also to the region around the lips, including cheeks and nose.