In face-to-face verbal communication, since the analysis and comprehension of the various articulatory movements relies on a bimodal perceptive mechanism for the continuous integration of coherent visual and acoustic stimula [331], the most natural way for visualizing the cues of speech on a a screen is that of synthesizing speech on a ``talking human face''. In this way a message from the computer (output) can be represented according to a bimodal model and visualized through a multimedia interface.
Worldwide interest is recently increasing around the possibility of employing anatomic models of a human face, suitable to synthetic animation through speech, for applications like the realization of multimedia man-machine interfaces, new algorithms for very low bitrate model-based videophony, advanced applications in the fields of education, culture and entertainment.
Different approaches have been investigated and proposed to define the basic set of parameters, necessary to model human mouth expressions including lips, teeth and tongue movements. In [38] 14 elementary visual units, responsible of the mouth shape, have been defined and associated to a corresponding acoustic class. Through suitable phonemic classification, a consistent sequence of visemes is obtained to visualize stable acoustic frames, while coarticulation transients are approximated by interpolation. In [139] a phonemic classifier is employed to determine a basic set of mouth parameters through sinthesis by rule, while in [231] the intermediate stage of phonemic classification is bypassed and input acoustic parameters are straightforward associated to suitable output visual parameters. All these approches, however, are unsuited to specific applications where a very faithful reproduction of the labial expressions is required such as those oriented to synthetic lipreading. The main problems stem from the lack of a suitable mouth anatomical model and from the coarse representation of the coarticulation phenomena.
A recent approach [61] based on Time-Delay Neural Networks
(TDNN) employs a novel fast learning algorithm capable to provide very
accurate and realistic control of the mouth parameters. As proven by the
experimental results, visible coarticulation parameters are correctly
estimated by the network and the corresponding visualization is smooth
enough to be comprehended by lipreading. In this work human faces have
been modeled through a flexible wire-frame mask suitably adapted to their
somatic characteristics with increasing resolution in correspondence to
high detail features like eyes and mouth. This kind of wire-frame is
generally referred to as 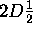 , meaning that it isn't neither a
2D nor a true 3D structure, but something in-between. A comparison can be
done with a carnival mask reproducing the characteristics of a human face
on a thin film of clay: the 3D information is incomplete since only one
half of the head is modeled by the mask. The wire-frame structure is
organized as a set of subregions, each of them affected by predefined
deformation rules producing time-varying variations to simulate muscle
contraction. Animation procedures have been designed on the basis of Ekman
and Friese [88] psychological studies, formalizing the
relationship between the subjective information content of the speaker's
audio-visual communication and his corresponding facial expression. In
particular, the set of basic animation units (AUs) defined
in [5] for facial mimics description and coding has been
implemented with reference the Parke model [257].
, meaning that it isn't neither a
2D nor a true 3D structure, but something in-between. A comparison can be
done with a carnival mask reproducing the characteristics of a human face
on a thin film of clay: the 3D information is incomplete since only one
half of the head is modeled by the mask. The wire-frame structure is
organized as a set of subregions, each of them affected by predefined
deformation rules producing time-varying variations to simulate muscle
contraction. Animation procedures have been designed on the basis of Ekman
and Friese [88] psychological studies, formalizing the
relationship between the subjective information content of the speaker's
audio-visual communication and his corresponding facial expression. In
particular, the set of basic animation units (AUs) defined
in [5] for facial mimics description and coding has been
implemented with reference the Parke model [257].