Note: the content of this page might change slightly; be sure to refresh right before you start
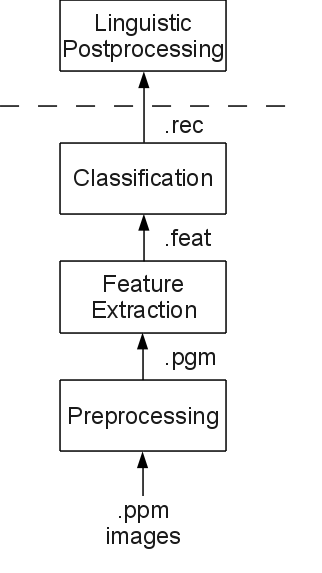
In this assignment, you will be using linguistic knowledge to improve the performance of the classifier.
Your program will get a variable number of arguments, each representing a
.rec-file (see previous assignment for the format of
these files; The value after each label is a distance, so lower is better).
The arguments are a single line of a page (not necessarily a complete
sentence).
The program must be called lp (not lp.sh or lp.py)
For training purposes, you can find .words-files in
/home/student/vakken/hwr/data/words. Each of these files corresponds to an
entire page, broken in lines, and each line broken in words.
You can use the wordsio.py file in the toolbox directory to read the
.words-files, or parse it yourself, since it is fairly straightforward XML.
For each of the .rec-files provided as arguments to your program, you print
on the standard output a line with the (possibly new) classification of that
word.
So, a typical interaction with your program would look like:
$ lp word1.rec word2.rec word3.rec word4.rec word5.rec word6.rec
in
den
Nederlandsche
Adel
te
verheffen
where lp is your program and $ represents the command line.
Hand in your code in a .tar.gz file, marked with your name and assignment
number. If there are compilation steps, create a Makefile, which compiles
your program with a single make command.
Your code should contain documentation on the decisions you took. This will make grading easier and help you when writing the final paper.
Last modified: May 26, 2011, by Jean-Paul van Oosten
Part of the HWR course